Making of a Data Scientist: A Memoir
Since the term ‘data science’ has existed only for about five years, there would be almost no one who grew up with the childhood dream of becoming a data scientist. I also started to introduce myself as a data scientist only for a few years, although the possi bility of data has enchanted me since my teen years, and I have continuously tried to collect and make use of data for a long time.
The short lifespan of data science means that there are not many established role models in becoming a data scientist. In a sense, everyone in the field is working while figuring out what it is. However, I believe that hearing of stories from those who started a bit earlier can still inform newcomers of what to do, or what not to do.
Here’s a story of how a data scientist is made…
Data Science for College Entrance Exam
Since childhood, I had a tendency to record facts and emotions. This is partly due to bad short-term memory, but I also have enjoyed the feeling of accumulating something over time, be it a journal, or a list of books I read. Sometimes these records made me proud, but more often I could find something I need to improve. Looking back, even as a child I had certain urge to collect data out of everything I was doing.
Then there came a time where I had the first major goal in life: going to a good college. Students in South Korea are known for their fierce competition to enter good schools, and I was no exception.
Since virtually all of my time was spent in studying for various exams, I naturally started to record various things about how I study. This included the time I spent on different activities (reading, writing, problem solving) and subjects (math, English, science), as well as what type of problems I get right or wrong once I take a quiz.
Remember that this is mid 90s where desktop computer were spreading, but virtually no one was using emails yet. While I was happy to use a grid paper for all my statistics and charts, I can imagine students of today can do the same thing much easily using a smartphone apps.
I wasn’t aware at that point, but I was effectively practicing data-driven method for studying. I tried to make sure I spent enough time on each activity and subject based on time statistics. Since I knew exact where my weakest points were, I could focus more efforts on those areas.
My school grades keep rising throughout my high school years, largely due to data-driven innovations. I’ve found time and place I was most productive at, and I kept improving how I study for a subject and prepare for an exam. While most Korean students rely on private institution, I decided to study on my own knowing that I can figure out the method that works best for me. Eventually I entered the most prestigious school, but more importantly I learned the value of data and data-driven innovations.
Eye-opening Possibility of Technology
I started to spend a lot of time attending CS courses although my major was EE. I realized that I liked to build something (i.e., software) that directly interface with a user , as opposed to something (i.e., hardware) that interface with a software. I was especially impressed by the ability of computer and internet that makes large amount of information accessible anywhere, and started to build a web-based tool for managing my schedule.
For the next 3 years, while working for a software company in Korea as a substitute for military service, I kept on improving the system, dubbed ‘MYLEO(Make Your Life ExtraOrdinary)’. MYLEO started as a simple calendar, but I added a feature where I can rate my schedule on a scale of A to F. The goal was to notice and improve what was unsatisfactory about my daily activities, in the same way I tried to optimize my studying routine during high school years.
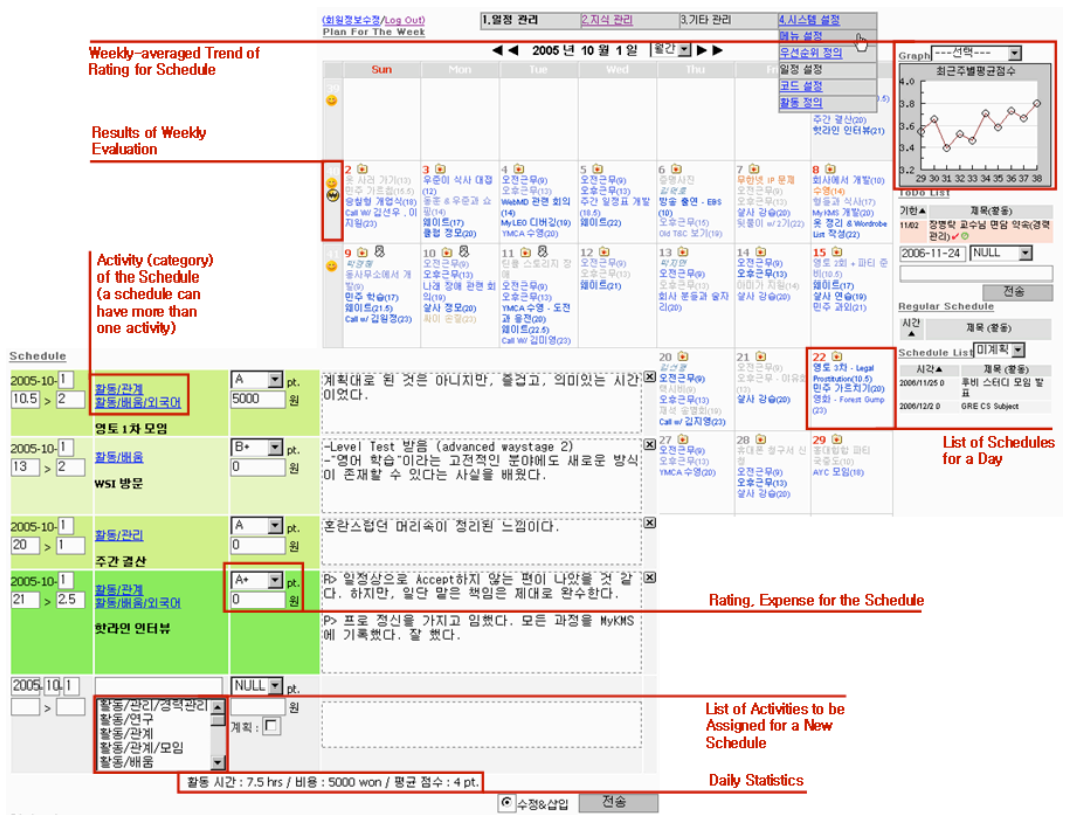
I kept adding various features to the tool, including fancy (at least so I thought) visualization for category-level breakdown of scores. I also added Wiki-like knowledge management system where I tracked what I learned. My colleagues called me crazy, because I was working every night to improve the tool. But they started to suggest various new features, and several of them eventually adopted the system for their personal information.
Having spent 3 years developing MYLEO, I was ready to bet my career on the potential of information technology and data-driven innovation. While I learned a lot while iterating on the software myself, I also realized that I needed to learn a lot more to start a serious career in the field. I started to look for graduate programs in the field of information management and retrieval, and got admission for Computer Science MS/Ph.D program in the University of Massachusetts, Amherst. <!–
Learning How Search Works
경험이라곤 회사와 개인 프로젝트로 소프트웨어를 개발하는 것이 전부였던 나에게, 대학원에서 배우는 최신의 인공지능과 검색 기술이 주는 가능성은 무궁무진한 것이었다. 그동안 내가 개발했던 일정 및 지식 관리 프로그램은 사용자가 손으로 일일히 모든 정보를 입력해야 하는 방식이었는데, 기계학습 및 자연어 처리 기술을 사용하면 사용자가 입력하는 텍스트에서 자동으로 주제 및 감정 정보를 뽑아내는 것도 가능하다. 또한 검색 기능을 사용하면 사용자가 일일이 정보를 분류하지 않아도 검색 엔진이 원하는 정보를 자동으로 찾아줄 수 있는 것이다.
대학원에서의 연구 주제는 구조화된 문서의 검색으로 잡았다. 검색 하면 무정형의 문서를 다루는 웹 검색을 주로 떠올리지만 사실 대부분의 문서에는 메타데이터라고도 하는 고유의 구조가 있다. 이메일에는 보내는 사람과 받는 사람, 그리고 날짜와 제목이라는 구조가 있고, IMDB와 같은 영화 데이터베이스를 검색한다면 영화의 출연진, 감독, 장르, 제목 등 다양한 구조를 떠올릴 수 있다. 이런 문서의 구조가 사용자의 질의어와 갖는 관계를 통계적 기법으로 추론해 이를 검색 랭킹에 반영하는 것이 연구의 핵심 아이디어었다.
이를 사례를 통해 알아보자. 영화 검색 엔진의 사용자가 ‘meg ryan romance’라는 질의어로 검색을 하려고 한다. 단순한 검색 알고리즘이라면 사용자의 질의어를 문서 전체와 매칭하려고 할 것이다. 하지만, 잘 생각해보면 질의어중 ‘meg ryan’에서 사용자가 의미한 것은 영화에 출연한 배우(cast)이고, ‘romance’는 영화의 장르(genre)일 것이라고 추론할 수 있다. 만약 검색 알고리즘이 이런 관계를 추론할 수 있다면, 사용자의 질의어를 문서 전체에서 찾는 대신에 특정 부분에서 찾을 수 있을 것이다. 나의 연구는 이런 아이디어를 바탕으로 알고리즘을 개발하고 이를 실험을 통해 증명한 것이다.
사용자의 질의어(‘meg ryan romance’)와 문서의 구조간의 관계 컴퓨터과학을 전공하는 미국의 대학원생들은 회사에서 인턴을 할 기회를 얻기위해 노력한다. 인턴 지원 및 프로젝트 과정에서 실제 회사에 지원해서 일하는 것이 어떤 경험인지 느낄 수 있고, 대학원 인턴의 경우 회사의 데이터와 프로젝트를 바탕으로 연구 논문을 쓸 수 있는 기회도 주어지기 때문이다. 나 역시 마이크로소프트에서 두번의 인턴을 경험하면서 학교에서 접하기 힘든 대용량 데이터를 분석하여 검색 엔진의 결과를 개인화시키는 기법에 대한 연구를 수행하였다. 인턴 중에 시애틀과 주변의 아름다운 자연 경관을 누릴 수 있었던 것은 보너스였다.
그 와중에 일어났던 또 다른 의미있는 변화는 스마트폰의 보급과 함꼐 자기 측정의 대중화를 주도한Quantified Self 운동의 확산이었다. 예전에는 데이터 수집, 처리, 분석까지 혼자 모든 것을 해야 했지만, 이제는 다양한 앱과 서비스를 사용하여 누구나 데이터 수집을 시작할 수 있게 된 것이었다. 또한 이런 개인들이 자신이 관심을 갖는 분석 주제를 공유하는 모임도 지역별로 생겨났다. 바야흐로 누구나 자신의 문제를 데이터로 해결할 수 있는 길이 열린 것이다.
이러한 변화에 발맞추어 나는 여러 프로그램에서 수집한 데이터를 모아서 종합해서 분석할 수 있게 해주는 프로그램을 만들기 시작했다. 예전에는 데이터 수집에서부터 분석, 그리고 시각화까지 모든 단계를 혼자 개발했지만, 데이터 입력은 에버노트나 모바일 앱에서, 데이터 가공 및 수집은 Ruby나 Python언어로, 시각화는 D3등의 웹 기반 시각화 툴을 사용하는 식이다. 대부분의 엡이나 서비스에서 데이터 입출력을 위한 API를 제공하기 시작했기에 가능한 일이었다.
내가 개인 행복도 측정을 위해 개발한 시스템 마침 근처의 보스턴에서 열린 첫번째 Quanified Self 모임에 참가할 수 있었던 나는 자신의 삶에서 일어나는 일을 데이터화하는 일에 열정을 가진 사람들이 이렇게 많아졌다는 것에 놀라지 않을 수 없었다. 그리고 2002년부터 다양한 방식으로 해왔던 개인 데이터 분석 프로젝트를 발표했을 때, 많은 사람들의 경탄과 함께 질문 세례가 쏟아졌다. 혼자 취미처럼 해왔던 일에 어느새 세상이 관심을 갖기 시작한 것이었다.
데이터 과학자로의 경력을 시작하다 대학원을 마치고 나는 검색과 데이터 분석에 대한 나의 흥미를 살릴 수 있는 직장을 구하기 위해 노력했다. 또한 박사과정을 이수하면서 개발보다는 연구가 내 적성에 맞는다는 사실도 느꼈다. 이 모든 조건을 충족시키는 곳은 인턴을 했던 마이크로소프트의 연구직이었다. 시애틀과 워싱턴주의 아름다운 경치에 끌린 점도 없다면 거짓말일 것이다. 그래서 2012년 여름 나는 시애틀에서 직장 생활을 시작하게 된다.
회사에서 연구자로서 시작하게 된 업무는 미국 검색 트래픽의 20%를 담당하는 빙(Bing) 검색엔진의 검색 결과를 평가하는 일이었다. 이는 구체적으로 주어진 검색 결과를 다양한 기준과 각도에서 평가하는 기법을 개발하고, 그 평가 결과를 실제로 검색 알고리즘을 개발하는 사람들에게 소통하는 일이다. 내 삶에서 다양한 데이터를 수집하여 분석하는 취미를 가졌고, 정보 검색을 전공한 나에게 이는 더할나위없이 흥미로운 일이었다.
대학원에서 검색 연구에 대한 다양한 경험을 쌓았지만, 회사 생활은 새로운 배움의 경험을 제공하였다. 실제 대용량 검색 서비스가 이루어지는 현장에서 부딛히는 어려움은 논문을 읽으며 상상했던 것과는 사뭇 다른 것이었다. 또한 마케팅, 개발, 디자인 등 다양한 배경의 사람들에게 연구자로서 나의 업무 성과를 이해시키는 것도 처음에는 쉬운 일이 아니었다. 이런 도전에도 불구하고 회사에 와서 데이터 과학의 다양한 모습을 접하고, 실제로 이론이 현실 세계의 문제를 풀어나가는 모습을 보면서 내가 선택한 길에 대한 보람을 느꼈다.
맺음말 지금까지 필자의 삶에서 ‘데이터 과학’과 연관지을 수 있는 부분을 요약해보았다. 여러분도 느꼈겠지만 필자는 어려서부터 데이터를 수집하고, 이를 바탕으로 현상을 개선하는데 관심을 가져왔다. 이는 아마 인류 역사가 시작된 이래에 수많은 사람들이 했을 노력이고, 여기에 데이터 과학이라는 이름이 붙게된 것은 극히 최근의 일이다. 이렇게 기술이 아니라 문제의식을 먼저 가지고 시작했기 때문에 필자는 다른 사람들이 ‘신기술’에 낭비하는 수많은 시간과 비용을 비판적으로 바라보게 되었다. 그리고 실제로 기계학습 기법이나 도구가 나왔을 때도 시도는 해보되, 실제 프로젝트에는 가급적 신중하게 도입하는 편이다.
그리고 필자는 비록 대학때부터 데이터 과학과 직접 관련된 전공을 선택하지는 않았지만, 대학원 공부를 통해 부족한 부분을 매꾸고 본격적인 데이터 과학의 세계로 뛰어들게 되었다. 필자가 걸어온 길이 가장 빠른 지름길은 아닐지도 모르지만, 누군가 처음부터 ‘올바른’ 전공을 선택하지 않은 것에 후회하냐고 묻는다면 아니라고 대답할 것이다. 필자가 거쳐온 다양한 삶의 경험이 현재 데이터 과학자로 일하는데 도움을 주고 있기 때문이다.
전자공학에서 배운 회로 설계나 전자장 등의 지식을 업무에 활용하는 것은 아니지만, 독학으로 프로그래밍과 고급 통계를 공부하면서 배양한 학습 능력이 그 단점을 상쇄한다고 믿는다. 또한 전자공학에 널리 쓰이는 미적분과 선형대수가 많은 기계학습 기법의 바탕이 된다는 것은 뜻하지 않은 수확이었다. 또한 대학때 잠깐 했던 디자인 공부도 나중에 정보시각화를 공부하는데 큰 도움이 되었다.
이처럼 데이터 과학에는 다양한 소양이 필요하며, 이런 의미에서도 통계/컴퓨터 전문가나 전공자에게만 열린 길은 아니다. 데이터 과학은 데이터라는 수단을 활용해 주어진 문제를 해결하는 과정이고, 누구나 자신의 문제에 데이터를 활용하는 방법을 배울 수 있기 때문이다. 데이터 과학에 대한 최소한의 지식을 쌓은 후에는 자신이 어떤 문제를 풀고 싶은지, 이를 위해 어떤 데이터를 활용할 수 있는지 묻는데서 출발해야 한다.
만약 장차 데이터 과학자를 꿈꾸고 있다면 데이터 과학자로서 어떤 문제를 해결하고 싶은지를 고민하기 시작해야 할 것이다. 일단 문제를 정하고 나면 어떤 도구와 분석 기법을 사용해야 할 것인지를 쉽게 결정할 수 있을 것이다. 또한 배운 내용을 문제 해결에 바로 적용하면서 지식을 자기 것으로 만들 수 있다. 반대로 어떤 특정한 기술을 무작정 배우는데서 출발한다면 시간 낭비가 될 가능성이 크고, 막상 실전에 나섰을 때는 또 다시 공부를 해야한다는 점을 깨닫게 될 것이다. –>