Designing Evaluation for Conversational Search Agent
People say that bot is the next big thing, and replace web and apps eventually. Every major tech company seems to have some form of voice interface, and the variety and capability of such agents (or bots) are growing. While building a bot that can actually help people would be a feat itself, how can we evaluate such systems? How can we generate training data for bot quality, and make decisions on whether the new bot is better or not?
As someone who worked on the evaluation of search systems for a long time, I decided to explore the possible evaluation / measurement method for bots or agents. I’ll focus on information-intensive tasks such as search and recommendation, but the framework itself would be general enough for other task types.
Web Search Engine vs. Conversational Search Agent
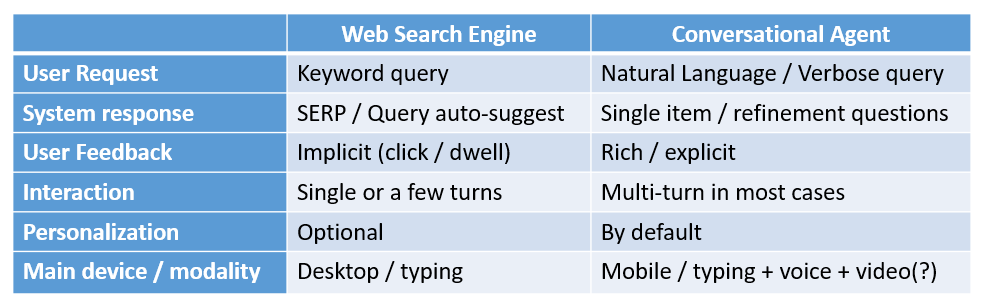
Let’s first consider the difference between current web search engine and conversational agent from evaluation standpoint. As you can see from the picture below, users in current web search engine type in keyword query followed by simple reformulation of original query. However, in conversational setting, users would likely use natural language query (or questions), followed by another NL questions.

What does this mean for metrics? It’s likely that we’ll have much higher diversity of ‘queries’, and ‘reformulations’ in conversational scenarios than current web search scenarios. Interactions would get likely longer and more complex since the agent can’t provide more than a few information items at a time. Also, while the feedback in current web search setting is mostly clicks, users would be able to provide rich (sometimes explicit) feedback on results in conversational setting. The table below summarizes the differences.
Evaluation of Conversational Search Agent: Review
So what would be the evaluation method suitable for the new settings? It turns out this is an area of active investigation in the area of dialog systems. And the classic evaluation method for a dialog system is called ‘PARADISE’, which is more of an umbrella/combo metric based on several different dimensions of quality, such as the success of interaction, efficiency of interaction, etc. Once the sub-metric is established, the weights for each metric is determined to maximize the fit with users’ subjective satisfaction ratings.

Another evaluation method is called Wizard-of-Oz (WOZ) study. As the name implies, WOZ is the method for establishing the upper-limit of performance for given task by having a person (Wizard-of-Oz) replacing the system without the user’s knowledge. Once the WOZ performance is established, then the systems can be compared among each other in the context of WOZ performance. Since Word Error Rate is a huge determinant of conversational system, the performance tends to be measured across multiple range of Word Error Rate.
The last method I plan to introduce today is called MeMo. This method is particularly interesting because it employs a conversational agent to evaluate other agents. The basic idea is to build an agent that mimics user to collect the data about the quality of the agent in question. The agent is built based on the history of user interaction and errors, to realistically model the user behavior.
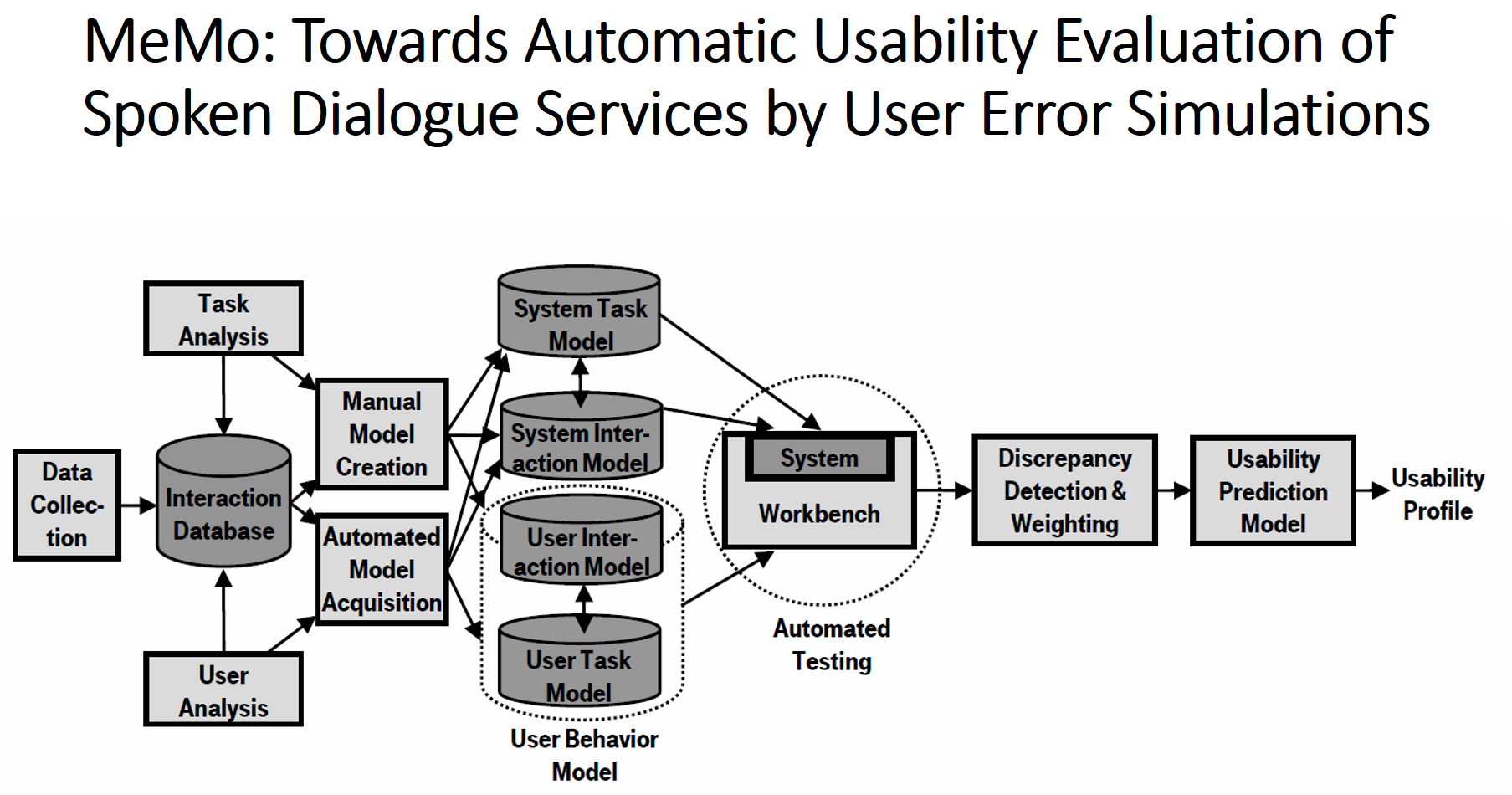
This is quite refreshing, and reminds me of recent AlphaGo’s approach in improving the performance by playing a Go match with itself. Unlike web search where the medium of communication is different between the agent and the user, since the conversational agent interact w/ the user both in natural language, there’s an opportunity to use another agent to train and improve the agent in question.
Conclusions: Where’s the Future?
So far we have found about the difference between web search and conversational search, and a few representative work on the evaluation of conversational search. (Imed and et al.’s recent work on Cortana evaluation is also worth looking) So, where’s the future? Predicting future is always a risky business, but we can make a few bets like below.
- There will be several metrics needed to capture a range of quality dimensions for conversational search (as in Paradise)
- Eliciting direct feedback from user will be more important, given the difficulty of traditional judging-based metric development
- In the long run, there will be agents specifically designed for evaluating and improving other intelligent agents
While conversational search is a new area, I believe many lessons we learned in web search will be valuable. With point (1), our current top-line metrics already are the product of combining several quality dimensions. Also, we have experience in explore-exploit for web search, which can be valuable for (2). But this area of conversational search will open up new areas of innovation like (3).
Appendix
Here are a few pointers. I found the book below particularly helpful. (available for download in Corpnet)